MCA Benches - GW2 Benchmark Tracker
Guild Wars 2 endgame raiding is, to a first approximation, a damage-optimization problem. For every build there is a known theoretical ceiling - the DPS you can squeeze out of a perfect rotation against a stationary training golem. The community site Snow Crows publishes those numbers as official benchmarks, and a big part of getting into a serious squad is proving you can get close to them.
My guild, [MCA] (join.mca.gg) - one of the top Guild Wars 2 raiding guilds, holding tens of active world records - wanted a way to track that, and to simplify planning by having a clear view of who can play what. The old workflow was the one every guild has: people paste dps.report links into a Discord channel, an officer squints at them, and the results live in a spreadsheet nobody fully trusts. That does not scale, and “did you actually run the right food?” is not a fun thing to verify by hand. So I built MCA Benches.
What it does
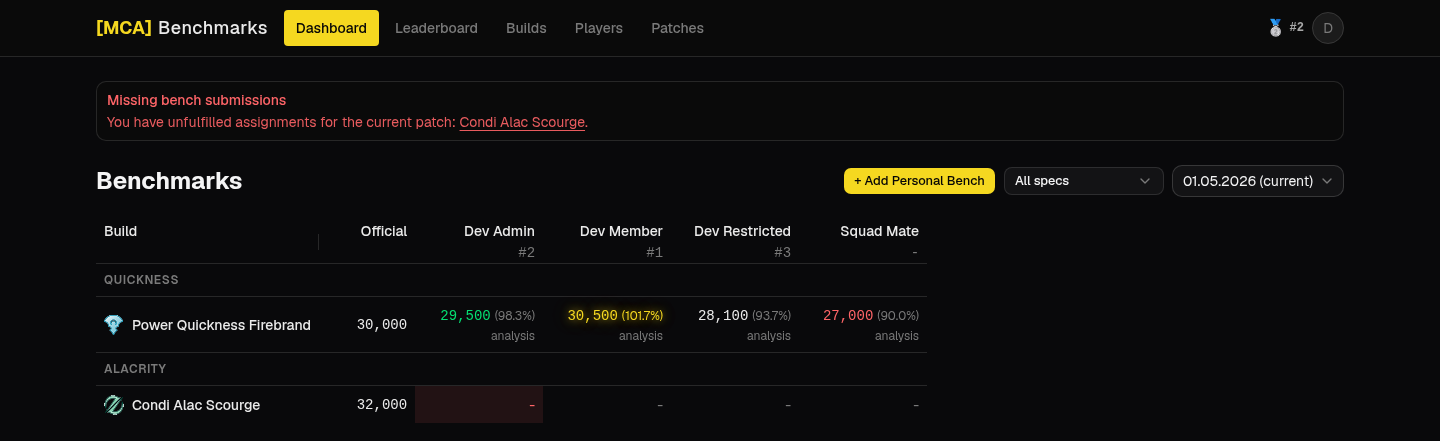
The app keeps, for every build, the official bench - a reference dps.report log plus its target number. Each player then submits their own attempt as a dps.report link, and the app:
- auto-validates the attempt against the official bench (right spec, weapons, food, buffs),
- diffs the rotation against the reference cast by cast,
- and ranks everyone on a leaderboard by how close their valid attempts get.
Ingesting logs
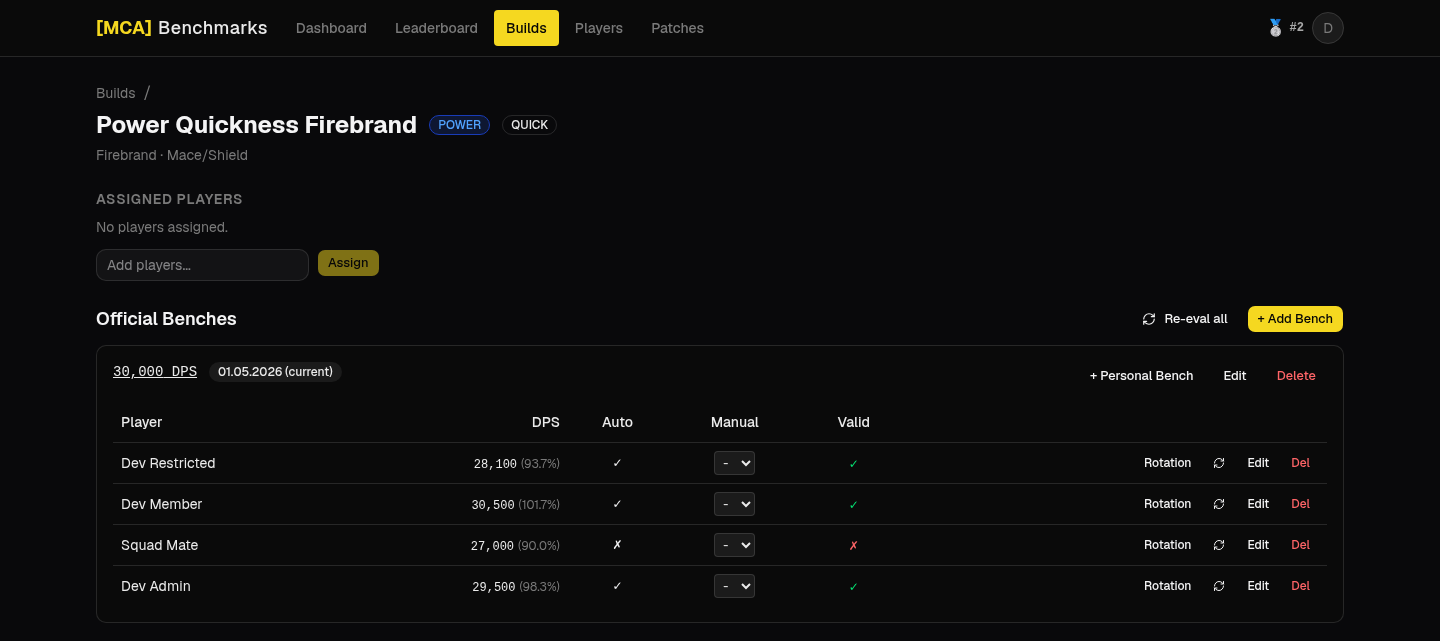
Everything starts from a single dps.report link. dps.report exposes a getJson endpoint, so the whole pipeline is: pull the permalink out of the URL, fetch the JSON, and read structured data out of one big blob. Logs are immutable once uploaded, so the fetch is force-cache and we never pay for the same log twice.
Out of that JSON I pull the DPS, the recorder’s account name, spec, weapon sets, consumables, buff uptimes, the full skill rotation, and the per-skill damage distribution. The rest of the app is really just a set of opinionated views over that structure.
Auto-validation
The tricky thing about “prove you hit the bench” is that a big number on its own means nothing. You can inflate DPS with the wrong food, an extra boon from a friendly source, or a weapon set the build never intended. So the official bench log is the source of truth, and a submission is only auto-valid if it matches on the things that actually change the result.
The check is a pure function - easy to unit test, and easy to reason about. It walks a list of rules and collects reasons to reject:
- Account - the log must be recorded by the account tied to that player.
- Spec - the log’s elite spec must match the build.
- Weapons - compared order-independent. I normalize each weapon set (sort within a set, then sort the sets) so that swapping which set is “first” does not register as a difference.
- Food - the nourishment buff must match the official one.
- Boons / conditions - the subtle one. Some builds scale damage per boon or per unique condition. So the count is only flagged when the build actually has a scaling modifier and your log carries more of them than the official log. Carrying fewer is your loss, not a cheat, so it passes.
- Damage-modifier uptimes - things like “hit from behind” or “target above 90% health”. If you kept a modifier up far more than the reference log did (beyond a tolerance), something about the encounter was easier than it should have been.
If nothing trips, the bench is auto-valid. Officers can still manually override either way, and that manual verdict wins over the automatic one.
Diffing rotations
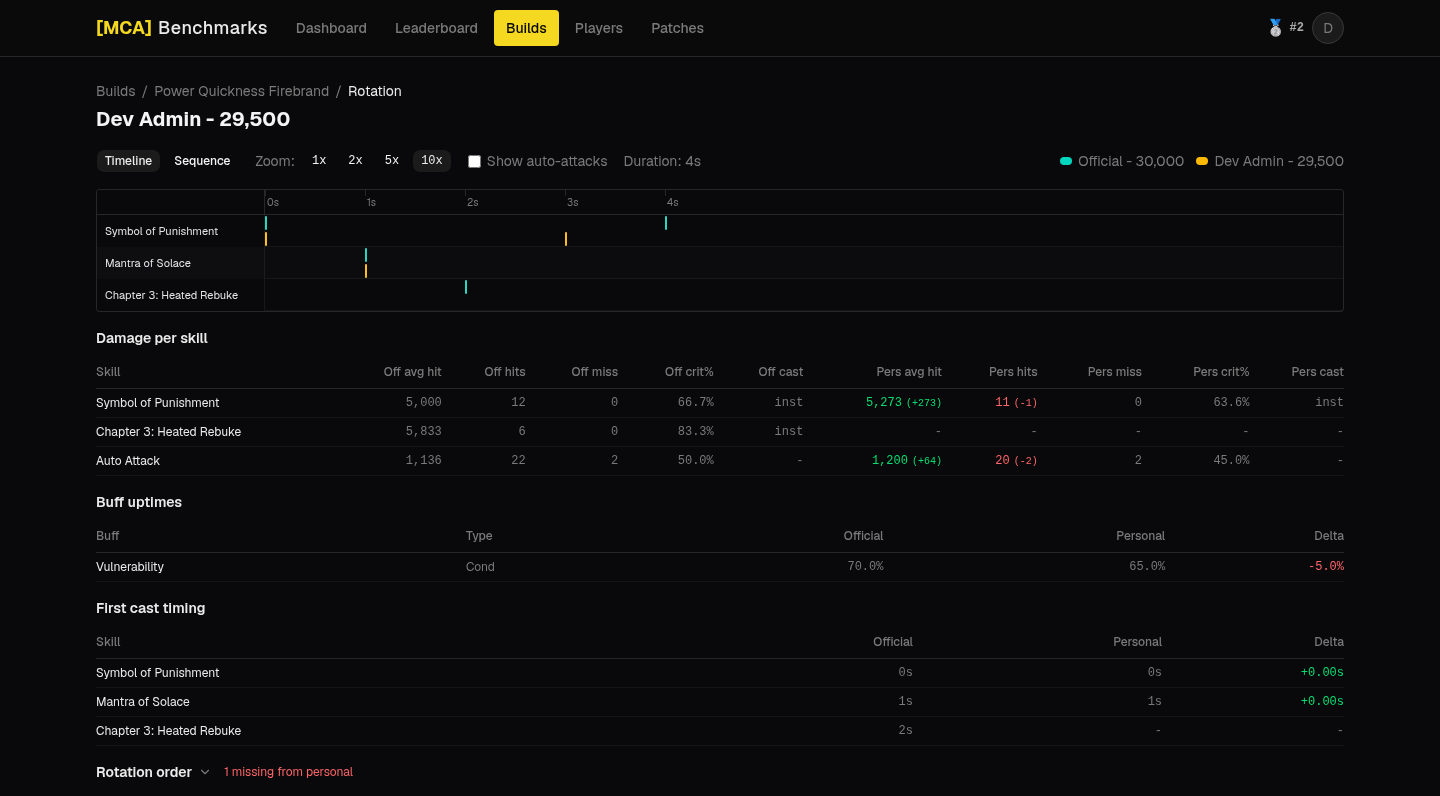
This is my favorite part. Two rotations are just two sequences of skill casts, and I want to line them up so a player can see exactly where they drifted: which casts match, which ones they skipped, and which ones they added that the reference never used.
That is a diff. The same problem git diff solves, and the same algorithm underneath: the longest common subsequence. I filter out auto-attacks and weapon swaps (pure noise here), then build the classic LCS table over skill IDs and backtrack it into match / official-only / personal-only rows:
// off[] and pers[] are the two cast sequences, by skillId
for (let i = 1; i <= n; i++) {
for (let j = 1; j <= m; j++) {
dp[i][j] =
off[i - 1].skillId === pers[j - 1].skillId
? dp[i - 1][j - 1] + 1
: Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
// backtrack: equal skill -> "match", otherwise step the side
// with the larger LCS value to emit an "only" rowThe backtrack walks from the bottom-right corner: when the two casts agree it emits a match and steps both sequences, otherwise it follows whichever neighbour preserved the longer subsequence and emits the dropped cast as official-only or personal-only. Rendered side by side with timestamps, you get a readable timeline of where a rotation fell apart, plus per-skill damage deltas and buff uptimes next to it.
The leaderboard
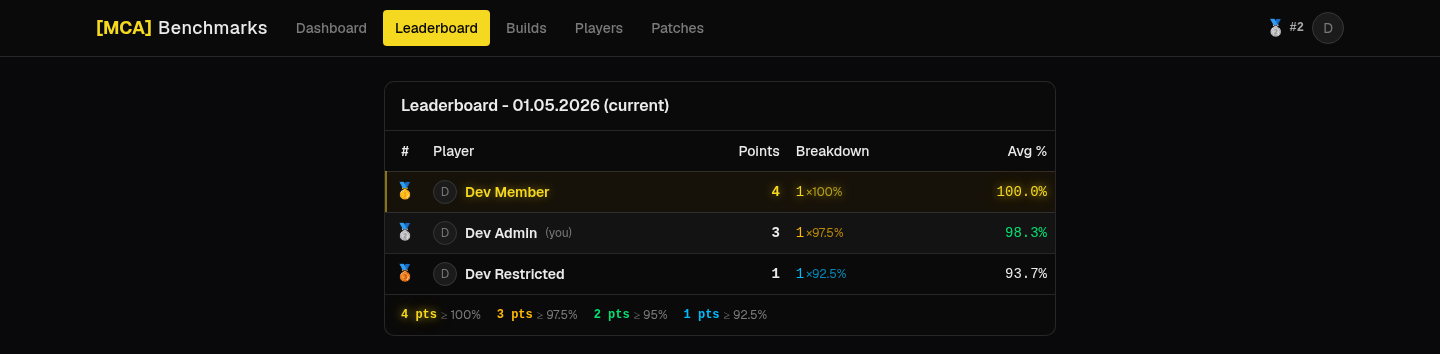
Ranking is deliberately forgiving: hitting 100% of a Snow Crows benchmark in a guild setting is unrealistic, so getting close should still be worth something. Each valid attempt is scored as a percentage of the official number and bucketed into points:
| Closeness to official | Points |
|---|---|
| ≥ 100% | 4 |
| ≥ 97.5% | 3 |
| ≥ 95% | 2 |
| ≥ 92.5% | 1 |
| below that | 0 |
Only a player’s best valid attempt per build counts. Points are summed across builds, ties broken by average percentage, and ranks assigned with standard competition ranking (“1224” - tied players share a rank and the next distinct row jumps past them).
Auth, for free
There is no user system. Access is Discord OAuth gated on guild-role membership: if you are in the [MCA] Discord with an allowed role, you are in. Trials get a restricted role that can submit and edit only their own benches and touch nothing else. None of the guild or role IDs are hardcoded - they come from env vars, so the whole thing can be forked and pointed at any guild. Locally there is a dev-login provider so you do not need a real Discord account, and it is hard-disabled in production (the app refuses to boot if it sees the dev flag next to a production database).
Architecture and the $0.40 bill
The whole thing is serverless and scales to zero. Next.js 15 (App Router) with Drizzle ORM, deployed via OpenNext onto Lambda behind CloudFront, talking to Aurora DSQL - a serverless, distributed Postgres.
flowchart LR User --> CF[CloudFront] CF --> Lambda[Next.js on Lambda] Lambda --> DSQL[(Aurora DSQL)] Lambda --> SM[Secrets Manager] Lambda -- getJson --> DPS[dps.report] EB[EventBridge weekly cron] --> Lambda Lambda -- webhook --> Discord
The detail I am quietly proud of: DSQL authenticates with IAM over a public endpoint, so the app needs no VPC, which means no NAT Gateway - the line item that silently dominates most “serverless” bills. Secrets live in Secrets Manager and are fetched at runtime rather than baked into the Lambda environment, so they never sit in plaintext config. A weekly EventBridge cron pings Discord to nudge players who still owe a bench for their assigned build.
The result is that an idle instance costs roughly $0.40 a month - a single Secrets Manager secret - and everything else (Lambda, CloudFront, DSQL, S3, logs) is pure pay-per-use that a low-traffic guild largely keeps inside the free tier.
It is open source under MIT and configurable for any guild, not just mine. Code is on GitHub.